Production update
Hackstone
This weekend I ran Hackstone, a hackathon for my classmates in Capstone, which was a great success. 13 students came over spring break to lock in on our projects, including me. We ran Checkpoints, demos modeled off Purdue Hackers, and had pizza.
Progress update
I have successfully finished Phase One of my production plan, and begun on further phases.
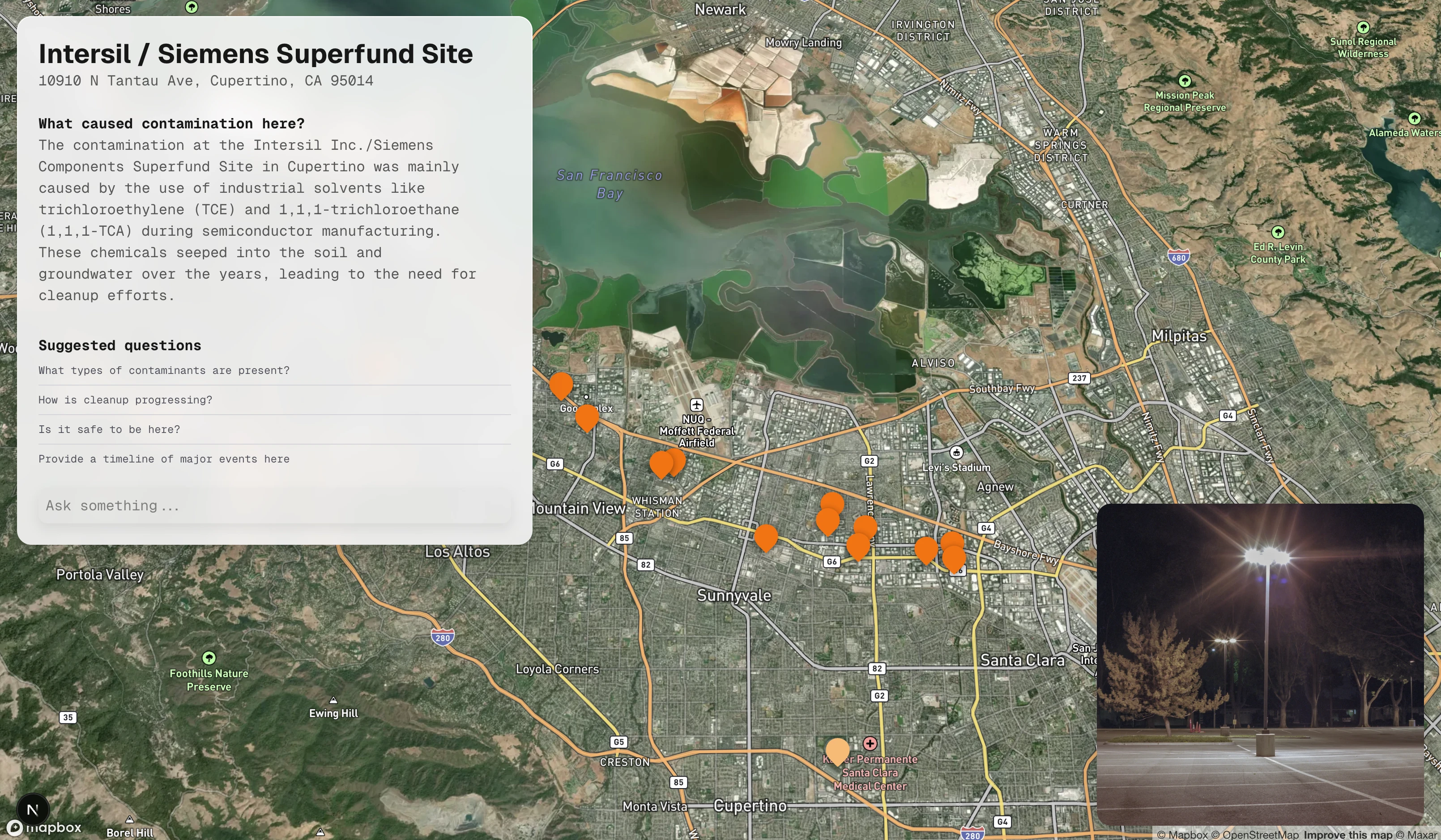
- Built a basic UI in Next.js for a map with an overlaid info panel (even if I'll rewrite all this code eventually)
- Built a flow for AI chat, where queries get sent to an edge function talking to ChatGPT through the Vercel AI SDK
- Written basic system prompt for tone/results
- Currently this is limited to one Superfund site for prototyping
- Researched my options for every level of the technical stack to understand all the steps going into the final architecture, and decided on what tools I'm using
- Built a full PDF processing pipeline, which runs OCR, Markdown conversion & cleanup on a sample PDF to use for RAG
This demo is running as a real Next.js app with real GPT-4o underpinning it, but is using text I manually extracted from one site’s PDFs instead of the full database/archive system. Both questions are typed in and live responses stream in word-by-word.
Technical architecture
The PDF processing, plus the RAG process, are turning out more complicated than I expected. I've worked with embeddings/vector databases before, plus LLM text generation UIs before, but combining the two with text from a PDF is an order of magnitude more complicated. I've figured out the following flow:
For documents’ preparation:
- Gather initial spreadsheet of all Superfund sites' metadata
- Requires deciding the scope of projects included, and the web perf implications of loading however much data
- Web scraping to download documents
- Decision of which documents to prioritize? Do we need all, or just the latest report?
- PDF to text
- Use LLM Vision model using zerox to convert to JSON with text of each page
- Markdown extraction from JSON into one document
- Markdown cleanup with LLM? (Useful if I want a text view of source files—remove images, page numbers, logos, repeated text)
- Embeddings 4. Generation with OpenAI/Ollama 5. Save to vector database
On query:
- Embed query
- Pull relevant documents' embeddings from database
- Run similarity search on embeddings
- Feed into LLM response
Then, a backend/frontend system for streaming the LLM responses to the website. Of these, I've built step 3 only, and the final step, but not the rest.
Open questions
- What tone do I want to strike?
- If the voice is too technical like the documents, it's glazed over/not helpful. If it's too casual, the site doesn't sound authoritative. There aren't casual names for many of the contaminants on these sites—1,1,1-trichloroethane is either referred to as such or as "dangerous chemical", it's not clear to me which is less unhelpful when there's no obvious class to put them in.
- Do I need the whole RAG pipeline?
- Using my hacked-together PDF text extraction fed into ChatGPT, the results are not necessarily representative of what I'll get based on full archives, but I'm not thrilled with thus far.
- Asking Perplexity Pro basic questions about Superfund sites gives great results even one-shot without refining prompts, that are often more readable/helpful. What if I skipped the complicated data backend
- What value am I providing, if you can ask an LLM about these sites already?
- Most people have never heard of Superfund, don't care, and don't understand. The map interface is a statement that you should care, and tries to make the data easy to navigate. Does that mean I should focus less on the archivist side of the project & the data backend, and almost entirely on the visualization & connection between sites, the teaching/research aspects?
- What if I focused on the development of silicon in South Bay & editorialized?
- The energy usage of running this document pipeline is non-trivial. Should I try to run it on local silicon with Ollama? Does it matter for the vibe of the project?
- How do I want to install the project in-person? Can I extend beyond the rectangular screen with projection etc?
Next steps
Before I focus a lot more on the UI, I want to get the data chunk sorted:
- Get a basic selection working, where the AI chat responds per-site instead of only for one
- Build database of initial sites to show on the map
- Figure out what context/data source I need for those to work, build data pipeline